TP3 : Listes, tuples et boucles
Lien vers le repository GitHub du TP : https://classroom.github.com/a/8UyWSW6k
Exercice 1
Reproduire ces jolies règles de multiplication que l’on trouve dans le Talkhys, un traité d’arithmétique d’Ibn Albanna, mathématicien marocain de la première moitié du XIIIe siècle (code à écrire dans exo_1.py)
1 × 1 = 1
11 × 11 = 121
111 × 111 = 12321
1111 × 1111 = 1234321
11111 × 11111 = 123454321
111111 × 111111 = 12345654321
1111111 × 1111111 = 1234567654321
11111111 × 11111111 = 123456787654321
111111111 × 111111111 = 12345678987654321
Exercice 2
Une liste peut être utilisée comme une représentation simple d’un polynôme, $P(x)$, où les éléments sont les coefficients des puissances de $x$ successives et les indices sont les puissances elles-mêmes. Ainsi le polynôme $P(x)=3+6x+2x^3$ sera représenté par la liste [3,6,0,2].
Pourquoi la tentative suivante pour dériver un polynôme échoue-t-elle (explication à fournir dans exo_2.md) ? Corriger exo_2.py en utilisant le moins de caractères possible.
P = [3, 6, 0, 2]
dPdx = []
for i, c in enumerate(P[1:]):
dPdx.append(i*c)
dPdx
[0, 0, 4]
Exercice 3
Utiliser une boucle for pour estimer π à partir des 20 premiers termes de la série de Madhava-Leibniz : $\pi=\sqrt{12}\left(1-\frac{1}{3\cdot 3}+\frac{1}{5\cdot 3^2}-\frac{1}{7\cdot 3^3}+\cdots\right)$
Code à écrire dans exo_3.py.
Exercice 4
Trier une liste de tuples les range dans l’ordre des premiers éléments de chaque tuple. Si deux premiers éléments sont identiques, on compare les deuxièmes, etc.
a = (3,1), (2,0), (1,4), (1,-1), (0,2)
a = list(a)
sorted(a)
[(0, 2), (1, -1), (1, 4), (2, 0), (3, 1)]
Cela suggère une méthode utilisant zip pour trier une liste en fonction des éléments d’une autre.
Mettre au point et utiliser cette méthode sur les données suivantes donnant le nombre d’heures d’ensoleillement pendant l’année 2018 dans différentes villes afin de trier ces villes de la plus ensoleillée à la moins ensoleillée (les données sont déjà écrites dans exo_4.py).
| Bordeaux | Brest | Limoges | Lyon | Marseille | Nantes |
|---|---|---|---|---|---|
| 2031 | 1676 | 1932 | 2145 | 2773 | 2101 |
| Nice | Paris | Pau | La Rochelle | Strasbourg | Tours |
| 2504 | 1995 | 1821 | 2424 | 2124 | 2050 |
Exercice 5
La loi de Benford prévoit la distribution des fréquences du premier chiffre des nombres présents dans divers ensembles de données. Cette distribution n’est pas uniforme : le chiffre 1 est plus souvent en première position que le 2, le 2 que le 3, et ainsi de suite.Cette loi peut par exemple se vérifier sur les prix dans un supermarché et a déjà été utilisée pour déceler des fraudes fiscales.
La probabilité pour que le chiffre $d$ soit en première position est donnée par la loi suivante : $P(d)=\log_{10}\left(\frac{d+1}{d}\right)$ La loi est d’autant mieux vérifiée que le jeu de données couvre plusieurs ordres de grandeur.
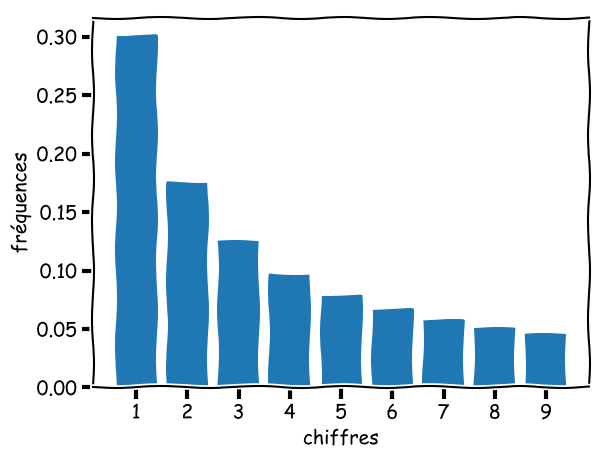
Démontrer à l’aide d’un programme (à écrire dans exo_5.py) que les premiers chiffres des 500 premiers éléments de la suite de Fibonacci suivent bien la loi.
Aide : pour récupérer le premier chiffre, on pourra transformer les éléments de la suite en chaîne de caractères puis transformer le premier caractère en entier avec int().